Les différents types de données structurées
Sciences numériques et technologie

Introduction
Les données constituent la matière première de toute activité numérique. Une donnée est la représentation d'une information. Afin de permettre
leur réutilisation, il est nécessaire de les conserver de manière persistante. Les structurer
correctement garantit que l’on puisse les exploiter facilement pour produire de l’information.
Cependant, les données non structurées peuvent aussi être exploitées, par exemple par les
moteurs de recherche.
Les données peuvent être conservées et classées sous différentes formes : textuelles (chaîne), numériques, images, sons, etc.
Les données variables qui font la souplesse d'un programme sont généralement lues depuis un appareil d'entrée utilisateur (clavier, souris…), un fichier, ou en réseau. Le processus d'enregistrement des données dans une mémoire s'appelle la mémorisation.
Repères historiques
Le stockage des données
L’évolution des capacités de stockage, de traitement et de diffusion des données fait qu’on assiste aujourd’hui à un phénomène de surabondance des données et au développement de nouveaux algorithmes capables de les exploiter. L’exploitation de données massives (Big Data) est en plein essor dans des domaines aussi variés que les sciences, la santé ou encore l’économie. Les conséquences sociétales sont nombreuses tant en termes de démocratie, de surveillance de masse ou encore d’exploitation des données personnelles.
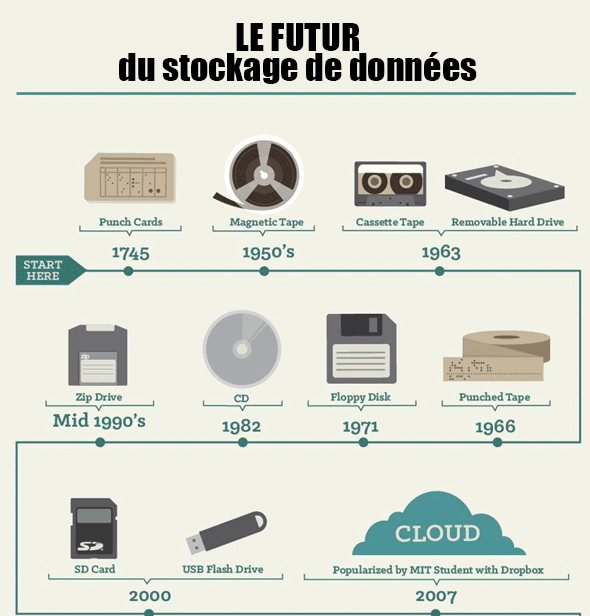
| Support | Capacité de stockage | Durée de vie |
|---|---|---|
| Carte perforée | 125 o | 50 ans |
| Bande magnétique | 1,4 Mo | 50 ans |
| Premier disque dur | 3,75 Mo | 15 ans |
| disquette 3 pouces 1/2 | 1,44 Mo | 15 ans |
| CD-rom | 650 Mo | 10 ans |
| DVD-rom | 4,7Go | 10 ans |
| Blu-ray | 30 Go | 10 ans |
| disque dur actuel 2,5 pouces | 1 To | 10 ans |
| Clé USB | 32 Go | 5 ans |
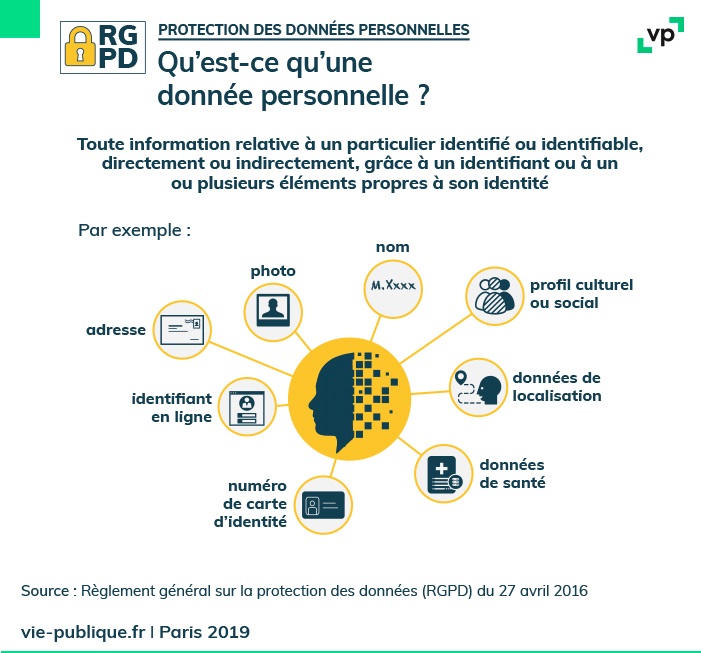
Données Personnelles
Entraînement 1 :
Classer par ordre croissant de capacité :
2000 octets, 15 Ko, 4 Go, 1,5 Mo, 1 To, 2 millions de bits, 2 000 000 bytes
Qu'est ce que le RGPD ?
L’acronyme RGPD signifie « Règlement Général sur la Protection des Données » (en anglais « General Data Protection Regulation » ou GDPR).
Le RGPD encadre le traitement des données personnelles sur le territoire de l’Union européenne.
Ce nouveau règlement européen s’inscrit dans la continuité de la Loi française Informatique
et Libertés de 1978 et renforce le contrôle par les citoyens de l’utilisation qui peut être faite des données les concernant.
Il harmonise les règles en Europe en offrant un cadre juridique unique aux professionnels.
Du point de vue de l’internaute, le RGPD met en place ou conforte un certain nombre de protections.
- Des conditions d’utilisation des données plus claires
- Recours, réparations et amendes
- Communication en cas de fuite
- Portabilité des données
- Consentement des mineurs
Données ouvertes ou Open Data
Certaines de ces données sont dites ouvertes (OpenData), leurs producteurs considérant qu’il s’agit d’un bien commun. Mais on assiste aussi au développement d’un marché de la donnée où des entreprises collectent et revendent des données sans transparence pour les usagers. D’où l’importance d’un cadre juridique permettant de protéger les usagers, préoccupation à laquelle répond le règlement général sur la protection des données (RGPD).
Les centres de données (datacenter) stockent des serveurs mettant à disposition les données et des applications les exploitant. Leur fonctionnement nécessite des ressources (en eau pour le refroidissement des machines, en électricité pour leur fonctionnement, en métaux rares pour leur fabrication) et génère de la pollution (manipulation de substances dangereuses lors de la fabrication, de la destruction ou du recyclage). De ce fait, les usages numériques doivent être pensés de façon à limiter la transformation des écosystèmes (notamment le réchauffement climatique) et à protéger la santé humaine.
On trouve énormément de données sur internet. Une partie de ces données sont publiques, par exemple le site data.gouv.fr récence un grand nombre de données publiques. Ces données sont librement réutilisables.
Entraînement 1 :
Afin de découvrir ce qu'est "l'open data", allez sur le site data.gouv.fr. En haut et à gauche de la page d’accueil, cliquez sur "Découvrez L’OpenData". Résumez en quelques lignes ce que vous aurez appris en lisant cette page.
Entraînement 2 :
Explorez pendant quelques minutes le site data.gouv.fr. Recherchez les données "Opérations coordonnées par les CROSS" à l'aide du moteur de recherche proposé par le site
Vous pouvez constater que ces données sont au format csv.
Le format CSV
Le format csv est très courant sur internet, nous allons l'étudier en premier.
Comma-separated values, connu sous le sigle CSV, est un format informatique ouvert représentant des données dans un tableau sous forme de valeurs séparées par des virgules.
Un fichier CSV est un fichier texte, par opposition aux formats dits « binaires ». Chaque ligne du texte correspond à une ligne du tableau et les virgules correspondent aux séparations entre les colonnes. Les portions de texte séparées par une virgule correspondent ainsi aux contenus des cellules du tableau.
Voici un exemple du contenu d'un fichier CSV :
nom,prenom,date_naissance
Durand,Jean-Pierre,23/05/1985
Dupont,Christophe,15/12/1967
Terta,Henry,12/06/1978
Sous forme de tableau :
| nom | prenom | date_naissance |
|---|---|---|
| Durand | Jean-Pierre | 23/05/1985 |
| Dupont | Christophe | 15/12/1967 |
| Terta | Henry | 12/06/1978 |
Nous avons ici 3 personnes :
- Jean-Pierre Durand qui est né le 23/05/1985
- Christophe Dupont qui est né le 15/12/1967
- Henry Terta qui est né le 12/06/1978
"nom", "prenom" et "date_naissance" sont appelés des descripteurs alors que, par exemple, "Durand", "Dupont" et "Terta" sont les valeurs du descripteur "nom".
Entraînement 3
Donnez les différentes valeurs du descripteur "date_naissance".
ATTENTION :
La virgule est un standard pour les données anglo-saxonnes, mais pas pour les données aux normes françaises. En effet, en français, la virgule est le séparateur des chiffres décimaux. Il serait impossible de différencier les virgules des décimaux et les virgules de séparation des informations. C’est pourquoi on utilise un autre séparateur : le point-virgule (;). Dans certains cas cela peut engendrer quelques problèmes, vous devrez donc rester vigilants sur le type de séparateur utilisé.
Les tableurs, tels que "Calc" (Libre Office) ou Excel (Microsoft), sont normalement capables de lire les fichiers au format CSV. J'ai précisé "normalement" car certains tableurs gèrent mal le séparateur CSV "point-virgule" et le séparateur des chiffres décimaux "virgule".
Entraînement 4 :
Après avoir téléchargé le fichier ident_pointVirgule.csv, ouvrez ce dernier à l'aide d'un tableur.
Si par hasard votre tableur ne gère pas correctement le fichier avec le séparateur "point-virgule", voici une version "séparateur virgule" du fichier : ident_virgule.csv
Dans la suite, gardez toujours cet éventuel problème à l'esprit (surtout avec des données "made in France")
Vous devriez obtenir ceci :
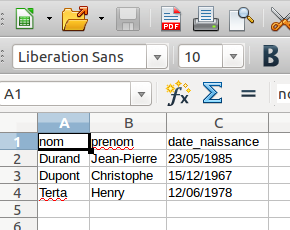
Vous pouvez constater que les données sont bien "rangées" dans un tableau avec des lignes et des colonnes (voilà pourquoi on parle de données tabulaires).
Il est possible de trouver sur le web des données beaucoup plus intéressantes à traiter que celles contenues dans le fichier "ident_pointVirgule.csv" (ou "ident_virgule.csv"). Par exemple, le site sql.sh, propose un fichier csv contenant des informations sur l'ensemble des communes françaises.
Entraînement 5 :
Ouvrez le fichier ville_point_virgule.csv à l'aide d'un tableur (c’est une version légèrement modifiée de celle disponible sur le site sql.sh, j’y ai notamment ajouté des entêtes). En cas de problème avec votre tableur, voici une version "séparateur virgule" : ville_virgule.csv (attention le séparateur "décimal" est ici le point)
Comme vous pouvez le constater, nous avons 15 colonnes (et 36700 lignes si on ne compte pas l'entête !), voici la signification de ces colonnes :
- dep : numéro de département
- nom : nom de la commune
- cp : code postal
- nb_hab_2010 : nombre d'habitants en 2010
- nb_hab_1999 : nombre d'habitants en 1999
- nb_hab_2012 : nombre d'habitants en 2012 (approximatif)
- dens : densité de la population (habitants par kilomètre carré)
- surf : superficie de la commune en kilomètre carré
- long : longitude
- lat : latitude
- alt_min : altitude minimale de la commune (il manque des données pour certains territoires d'outre-mer)
- alt_max : altitude maximale de la commune (il manque des données pour certains territoires d'outre-mer)
Les trois dernières colonnes ne comportent pas de descripteurs, nous ne nous en occuperons pas pour l'instant.
- En utilisant la fonction "rechercher" du tableur, déterminez l'altitude maximale et l'altitude minimale de Paris.
- En utilisant la fonction "trier" du tableur, classer les 5 communes Guadeloupéennes les plus peuplées par ordre croissant.