Le fonctionnement du Web : le protocole HTTP
Sciences numériques et technologie (SNT)

Un protocole est ensemble de règles qui permettent à 2 ordinateurs de communiquer ensemble.
HTTP (HyperText Transfer Protocol) est un protocole qui permet de récupérer des ressources telles que des documents HTML. Il est à la base de tout échange de données sur le Web.
Le but du protocole HTTP est de permettre un transfert de fichiers (essentiellement au format HTML) localisés grâce à une chaîne de caractères appelée URL entre un navigateur (le client) et un serveur Web :
- Le navigateur effectue une requête HTTP : principalement GET et POST
- Le serveur traite la requête puis envoie une réponse HTTP
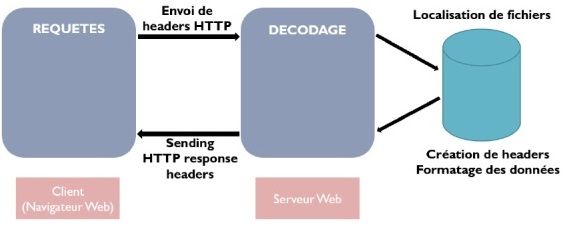
Voici une version simplifiée de la composition d'une requête HTTP (client vers serveur) :
- la méthode employée pour effectuer la requête
- l'URL de la ressource
- la version du protocole utilisé par le client (souvent HTTP 1.1)
- le navigateur employé (Firefox, Chrome) et sa version
- le type du document demandé (par exemple HTML)
- ...
Certaines de ces lignes sont optionnelles. Vous pouvez visualiser vos entêtes en utilisant la touche F12 dans votre navigateur onglet "Headers".
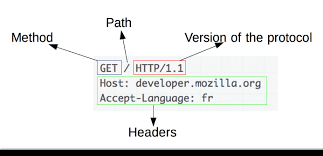
Un autre exemple de requête HTTP :
GET /mondossier/monFichier.html HTTP/1.1
User-Agent : Mozilla/5.0
Accept : text/htmlNous avons ici plusieurs informations :
- "GET" est la méthode employée (voir ci-dessous)
- "/mondossier/monFichier.html" correspond l'URL de la ressource demandée
- "HTTP/1.1" : la version du protocole est la 1.1
- "Mozilla/5.0" : le navigateur web employé est Firefox de la société Mozilla
- "text/html" : le client s'attend à recevoir du HTML
Revenons sur la méthode employée :
Une requête HTTP utilise une méthode (c'est une commande qui demande au serveur d'effectuer une certaine action). Voici la liste des méthodes disponibles : GET, HEAD, POST, OPTIONS, CONNECT, TRACE, PUT, PATCH, DELETE
Détaillons 4 de ces méthodes :
| Commandes | Particularités |
|---|---|
| GET | C'est la méthode la plus courante pour demander une ressource. Elle est sans effet sur la ressource. |
| POST | Cette méthode est utilisée pour soumettre des données en vue d'un traitement (côté serveur). Typiquement c'est la méthode employée lorsque l'on envoie au serveur les données issues d'un formulaire. |
| DELETE | Cette méthode permet de supprimer une ressource sur le serveur. |
| PUT | Cette méthode permet de modifier une ressource sur le serveur |
Réponse du serveur à une requête HTTP
Une fois la requête reçue, le serveur va renvoyer une réponse, voici un exemple de réponse du serveur :
HTTP/1.1 200 OK
Date: Thu, 15 feb 2019 12:02:32 GMT
Server: Apache/2.0.54 (Debian GNU/Linux) DAV/2 SVN/1.1.4
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=ISO-8859-1
<!doctype html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Voici mon site</title>
</head>
<body>
<h1>Hello World! Ceci est un titre</h1>
<p>Ceci est un <strong>paragraphe</strong>. Avez-vous bien compris ?</p>
</body>
</html>Nous n'allons pas détailler cette réponse, voici quelques explications sur les éléments qui nous seront indispensables par la suite :
Commençons par la fin : le serveur renvoie du code HTML, une fois ce code reçu par le client, il est interprété par le navigateur qui affiche le résultat à l'écran. Cette partie correspond au corps de la réponse.
La 1re ligne se nomme la ligne de statut :
- HTTP/1.1 : version de HTTP utilisé par le serveur
- 200 : code indiquant que le document recherché par le client a bien été trouvé par le serveur. Il existe d'autres codes dont un que vous connaissez peut-être déjà : le code 404 (qui signifie «Le document recherché n'a pu être trouvé»).
Les 5 lignes suivantes constituent l'en-tête de la réponse, une ligne nous intéresse plus particulièrement :
Server: Apache/2.0.54 (Debian GNU/Linux) DAV/2 SVN/1.1.4
Le serveur web qui a fourni la réponse http ci-dessus a comme système d'exploitation une distribution GNU/Linux nommée "Debian" (pour en savoir plus sur GNU/Linux, n'hésitez pas à faire vos propres recherches). "Apache" est le coeur du serveur web puisque c'est ce logiciel qui va gérer les requêtes http (recevoir les requêtes http en provenance des clients et renvoyer les réponses http). Il existe d'autres logiciels capables de gérer les requêtes http (nginx, lighttpd...) mais, aux dernières nouvelles, Apache est toujours le plus populaire puisqu'il est installé sur environ la moitié des serveurs web mondiaux !
Liste des codes HTTP
Même en tant que simple internaute, on peut être confronté à des codes de réponse HTTP (par exemple quand on tape une URL incorrecte).
- Informational 1XX : Ces codes ne sont pas utilisés dans la version 1.0 du protocole
- Successful 2XX : Ces codes indiquent le bon déroulement de la transaction
- Redirection 3XX : Ces codes indiquent que la ressource n'est plus à l'emplacement indiqué
- Client Error 4XX : Ces codes indiquent que la requête est incorrecte
- Server Error 5XX : Ces codes indiquent qu'il y a eu une erreur interne du serveur

Protocole HTTPS
Le HTTPS est la version "sécurisée" du protocole HTTP. Par "sécurisé" en entend que les données sont chiffrées avant d'être transmises sur le réseau.
Voici les différentes étapes d'une communication client - serveur utilisant le protocole HTTPS :
- le client demande au serveur une connexion sécurisée (en utilisant "https" à la place de "http" dans la barre d'adresse du navigateur web)
- le serveur répond au client qu'il est OK pour l'établissement d'une connexion sécurisée. Afin de prouver au client qu'il est bien celui qu'il prétend être, le serveur fournit au client un certificat prouvant son "identité". En effet, il existe des attaques dites "man in the middle", où un serveur "pirate" essaye de se faire passer, par exemple, pour le serveur d'une banque : le client, pensant être en communication avec le serveur de sa banque, va saisir son identifiant et son mot de passe, identifiant et mot de passe qui seront récupérés par le serveur pirate. Afin d'éviter ce genre d'attaque, des organismes délivrent donc des certificats prouvant l'identité des sites qui proposent des connexions "https".
- à partir de ce moment-là, les échanges entre le client et le serveur seront chiffrés grâce à un système de "clé publique - clé privée" (nous n'aborderons pas ici le principe du chiffrement par "clé publique - clé privée"). Même si un pirate arrivait à intercepter les données circulant entre le client et le serveur, ces dernières ne lui seraient d'aucune utilité, car totalement incompréhensible à cause du chiffrement (seuls le client et le serveur sont aptes à déchiffrer ces données)
D'un point vu strictement pratique il est nécessaire de bien vérifier que le protocole est bien utilisé (l'adresse commence par "https") avant de transmettre des données sensibles (coordonnées bancaires...). Si ce n'est pas le cas, passez votre chemin, car toute personne qui interceptera les paquets de données sera en mesure de lire vos données sensibles.